


Amazon Redshift: The Key to Building a Modern Data Architecture
The Data Warehousing Market is expected to Reach USD 85.7 Billion by 2032, experts in cloud-based data warehouse solutions are now more valuable than ever!
Our virtual one-day training course, "Building Data Analytics Solutions Using Amazon RedShift" provides guidance for engineers, platform architects and other professionals to develop modern architectures that include this incredibly popular service as part of their analytics pipelines – giving them great potential for successful careers over the coming years ahead.
Before getting to know the course, do you know what Data warehousing is?
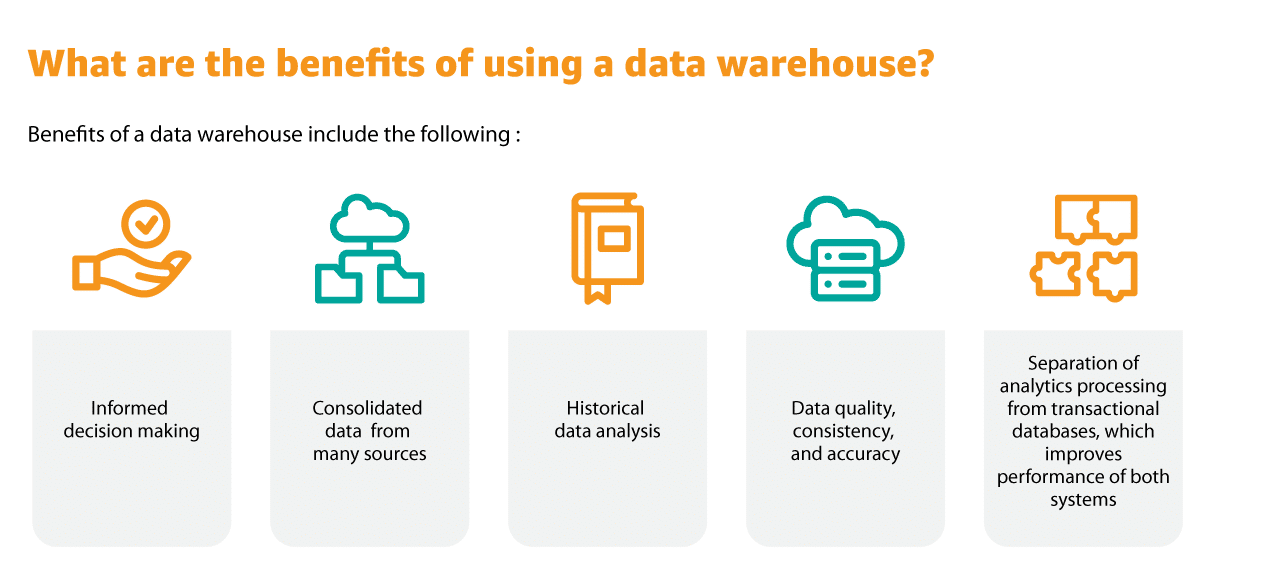
Data is the cornerstone of success in today's business landscape, and a data warehouse serves as its central hub.
Transactional systems, relational databases, and other sources feed into this repository to provide organizations with an ever-growing source of information that can be accessed by decision makers using various BI tools or analytics applications.
Business users derive immense value from analyzing their data; they use it to drive performance, inform decisions and gain invaluable insights for maximum efficiency.
Data warehouses are the backbone to today's business intelligence systems, allowing them to generate powerful reports, visualizations and analytics with minimal I/O while still being able to serve hundreds of users at once.
Have you ever wondered how all your data comes together in one cohesive, organized hub?
Data warehouses are an integral part of modern information systems – they store and manage large amounts of data from multiple sources as well as aid with analysis.
Within a database, different pieces like tables and columns hold the key to understanding what each field contains such as integers or strings. Schemas serve almost like folders that help keep everything neat, so query tools know exactly which parts need accessing for analyzing purposes.
How do data warehouses, databases, and data lakes work together?
Businesses everywhere are finding ways to make the most of their data by combining a suite of storage and analysis tools. By integrating databases, data lakes, and warehouses using Amazon Redshift's Lake house architecture, it is possible for companies to unlock more insights from their ever-expanding pool information.
With some creativity in implementing these patterns into your infrastructure you can build an effective system which leverages all its components for maximum benefit!
![]()
Image (above): Land data in a database or datalake, prepare the data, move selected data into a data warehouse, then perform reporting.
![]()
Image (above): Land data in a data warehouse, analyze the data, then share data to use with other analytics and machine learning services.
Data warehouses are designed to provide insight into data relationships and trends, storing details of transactions in an organized tabular format.
However, a data lake offers the opportunity for more expansive analysis beyond these capabilities; instead acting as a repository that accepts all forms of structured or unstructured input – opening possibilities like big-data analytics, full text searches and machine learning applications!
Where does data warehousing stand today?
Data warehouses have become a cornerstone of advanced data architecture and can be used to produce transformative insights. With the capability of using SQL commands, they allow for powerful mixed analytics across multiple sources without unnecessary migration or manipulation – unlocking opportunities that come with building machine learning models in-house.
This importance is reflected by what employers demand, as evidenced through an IDC survey which highlighted SQL proficiency as essential when working alongide data lakes & warehouses today.
Amazon Redshift, a cloud data warehouse service, integrates with data lakes based on Amazon S3 and relational database services, such as Amazon Relational Database Service (Amazon RDS) for PostgreSQL, Amazon Aurora PostgreSQL-Compatible Edition, Amazon RDS for MySQL, and Amazon Aurora MySQL-Compatible Edition.
It also supports building and using ML models using familiar SQL commands, thereby reducing the skills needed to take advantage of ML.
As data continues to grow exponentially, the cost-effective operation of a data warehouse becomes even more important. Amazon Redshift supports cost-effective operations by separating the scaling of storage from compute and maintains query performance with the help of features such as Advanced Query Acceleration (AQUA) and advanced workload management.
In addition, Amazon Redshift uses ML-powered features to reduce the performance and maintenance burden on database administrators.
Stay Ahead of the Game: Leverage Amazon Redshift's Capabilities for Cloud-Native Solutions
Organizations must equip themselves with the necessary skills to capitalize on Amazon Redshift's powerful capabilities, whether transitioning from an on-premises data warehouse or building a cloud native solution.
Doing so gives them access to ground-breaking opportunities and streamlined performance that can elevate their success in this digital age.

Discover the new Building Data Analytics Solutions Using Amazon Redshift course.
Expert AWS instructors will guide you through the process of building a data analytics pipeline using Amazon Redshift in an interactive environment during our intermediate-level, one-day Building Data Analytics Solutions Using Amazon Redshift course.
You'll learn three major skills:
- How to leverage the separation of compute and storage
- How to analyze all your data regardless of its location—a data warehouse, data lake, or relational database, such as Amazon Aurora
- How to leverage ML-powered automation to reduce maintenance burden
| Course Code | Course Title | Fees (RM) | Days | May-24 | Jun-24 | Jul-24 |
|---|---|---|---|---|---|---|
| AWS-BDAS | Building Data Analytics Solutions Using Amazon Redshift | 1,800 | 1 | – | 12 | – |





















